
Pandas vs. Polars: Which is Better for Data Processing?
In the world of data processing, efficiency, speed, and ease of use are paramount. With the increasing volume of data that needs to be handled, choosing the right tool can make a significant difference in performance and productivity. Two of the most popular libraries in the Python ecosystem for data manipulation are Pandas and Polars. Both libraries offer powerful features for working with data, but they differ in their design, performance, and use cases. This blog post delves into the key differences between Pandas and Polars, helping you decide which is better for your data processing needs.

1. Performance and Speed
When it comes to performance, Polars often takes the lead, especially for large datasets. Polars is designed from the ground up for high performance, leveraging multi-threading and optimized algorithms to process data quickly. In many benchmarks, Polars outperforms Pandas, particularly with operations on large datasets that would take Pandas much longer to complete.
On the other hand, Pandas is no slouch, particularly for small to moderately sized datasets. While Pandas might lag behind Polars in terms of raw speed for massive datasets, its performance is still very respectable for many typical data analysis tasks. Moreover, Pandas has been extensively optimized over the years, and for smaller tasks, it might actually perform faster due to its lower overhead.
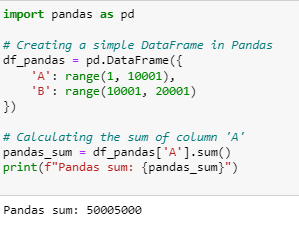
Example: Calculating the Sum of a Column
Here’s how you can perform a simple sum operation on a column using both Pandas and Polars:
- Pandas:
- Polars:
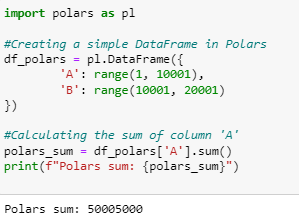
Both Pandas and Polars can easily handle this operation, but for larger datasets, you might start to see a performance difference, with Polars pulling ahead.
2. Memory Usage
Polars is more memory-efficient compared to Pandas. This efficiency comes from Polars' columnar data storage and its ability to avoid unnecessary data copies during operations. Polars' design allows it to handle larger-than-memory datasets more effectively, making it a better choice when working with extremely large data.
Pandas, while powerful, can be more memory-intensive, particularly when dealing with very large datasets. It often requires more memory to hold data in memory and perform operations on it. For users working on machines with limited memory resources, this can be a limitation.
Example: Filtering Data
Here’s how you can filter data using both Pandas and Polars:
- Pandas:

- Polars:

Both libraries offer straightforward filtering capabilities, but again, Polars’ memory efficiency might be more apparent as the dataset size grows.
3. API and Ease of Use
Pandas has been the go-to library for data manipulation in Python for many years. Its API is highly expressive and well-documented, with a vast number of functions and methods that make it easy to perform complex data transformations. The Pandas API is intuitive for those familiar with Python and its data structures, making it easy to pick up and use effectively.
Polars, while newer, has a similar API to Pandas, but with some differences. It introduces a more functional programming style, which can be a bit unfamiliar to users who are accustomed to Pandas' more imperative style. However, once you get used to it, Polars can be just as easy to use as Pandas, and its API is continually improving as it gains adoption.
4. Community and Ecosystem
Pandas has a massive user base and a rich ecosystem of extensions, tutorials, and resources. Whether you're looking for a specific function, trying to solve a tricky problem, or seeking advice from other data scientists, you're likely to find a solution within the Pandas community. This extensive support makes Pandas a great choice for beginners and seasoned professionals alike.
Polars, being newer, has a smaller but rapidly growing community. While it might not have as many resources as Pandas yet, the community is active and supportive. The documentation is robust, and the Polars team is continuously working on improving the library and expanding its capabilities.
5. Use Cases
Pandas is the go-to choice for:
- Small to Medium-Sized Datasets: Pandas is ideal for datasets that can comfortably fit into memory and for tasks that don’t require extreme performance.
- Data Analysis and Exploration: With its rich API and intuitive operations, Pandas is excellent for data exploration and analysis, especially in Jupyter notebooks.
- Integration with the Python Ecosystem: Pandas integrates seamlessly with other Python libraries like Matplotlib, Seaborn, and Scikit-learn, making it perfect for end-to-end data science workflows.
Polars is the go-to choice for:
- Large Datasets: If you’re working with massive datasets that push the limits of memory, Polars is more likely to handle the workload efficiently.
- High-Performance Needs: For tasks that require speed, such as real-time data processing or working with very large CSV files, Polars often provides better performance.
- Scalability: Polars is designed to scale efficiently, making it suitable for production environments where performance and memory efficiency are critical.
Which Is Better?
The choice between Pandas and Polars ultimately depends on your specific needs. If you’re dealing with large datasets and need the best possible performance, Polars might be the better option. However, if you’re working with smaller datasets or need the extensive ecosystem and support that comes with a mature library, Pandas is still an excellent choice.
Both libraries are powerful tools in the data processing landscape, and knowing when to use each one can significantly improve your workflow. Whether you choose Pandas or Polars, understanding their strengths and weaknesses will help you make more informed decisions in your data processing tasks.
0 comments:
Post a Comment